8 minutes
Speeding up pattern matching with WebAssembly
I while ago I was tasked to find predefined patterns in strings, a well known problem in computer science. Our algorithm was running on AWS Lambda using the Node.js runtime, and, considering that we sometimes needed to search through billions of strings, performances of this algorithm were crucial.
On the other hand I recently paid a lot of attention to WebAssembly and Rust, both technologies seem really promising and attract a growing interest from developers. After reading a few articles on performance improvement using Wasm (the acronym for WebAssembly), I decided to give it a try: could it speed up my Lambda function?
Pattern matching
Before even talking about WebAssembly, let’s dig a bit into the pattern searching problem: We are given a set of patterns and a string, and the goal is to find all patterns that appear in the string.
// Patterns
["Charizard", "Magikarp", "Splash", "Flamethrower"]
// The string
"Magikarp used Splash! But nothing happened."
/* ^^^^^^^^ ^^^^^^ */
// Output
["Magikarp", "Splash"]
When looking for only one pattern the problem is simple: go through the string character per character and if the current one matches the first character of the pattern, then we compare the next caracter to the second of the pattern and so on. This can be represented using an automaton:

Regular expressions (regexes) are an extension of this algorithm, where the automaton can be more evolved:

In the example above, the regex is equivalent to searching for both patterns “charmander” and “charizard”. Of course, regexes are very expressive and can match much more complex patterns, but in this article we are only interested in plain text patterns.
Trying to write a single regex to match a thousand patterns or using a thousand regexes is probably not a good idea, however. For those use cases there is another algorithm much more effective called Aho-Corasick.
The idea is to build a deterministic finite automaton (meaning that there is always exactly one possibility when transitioning from one state to another) that takes advantages of common suffixes and prefixes.
The Aho-Corasick algorithm uses a ‘failure function’: for a given state if no transition corresponds to the next character, the failure function kicks in and tell us which is the next state.

For instance in the above example, after recognizing lapra of lapras, if the next character is not an s, then no need to go back and try other branches of the automaton: the failure function tells us that we can continue from the first a state of rapidash. Again if the next character is not a p, we can continue from a state of articuno and so on.
If you are interested in how to build the automaton, you can find a commented implementation in C++ here. If you prefer Rust, I wrote a (less commented) Rust version for the sake of this experiment.
From a practical point of view, the Aho-Corasick algorithm consist in two phases:
- Building the automaton: in linear time, performances of this step are not critical and building time will be neglected by comparison to the execution step.
- Executing the automaton: this is the phase I’m interested in, it is mainly about look up into the transition and failure function tables built at the previous step.
What is interesting is that this task does not involve heavy computation as graphic or cryptography may require, which would be the type of tasks that make WebAssembly shine: still, can Wasm speed-up pattern matching?
Speeding things up
Now that we are up to date with the algorithm, here is a good JavaScript implementation that I used as reference. The plan was to write a Rust version, compile it to Wasm and check if it is faster.
In order to compare performances I needed to create a benchmark. I picked a little over 8,000 distinct random words from Les Misérables, a 68,000 lines long novel by Victor Hugo. The task is to find all occurrences of these 8,000 words in the whole novel.
A failed attempt
I wrote a first version of Aho-Corasick in Rust using wasm-bindgen to generate glue code between JavaScript and WebAssembly.
#[wasm_bindgen]
pub struct Matcher {
...
}
#[wasm_bindgen]
impl Matcher {
pub fn new(words: &js_sys::Array) -> Matcher {
...
}
pub fn run(&self, string: String) -> js_sys::Array {
...
}
}
I built a release build targeting Node.js
wasm-pack build --release --target nodejs
Then timed both je JavaScript and WebAssembly version:
time NODE_ENV=production node wasm.js
time NODE_ENV=production node js.js
And surprise:
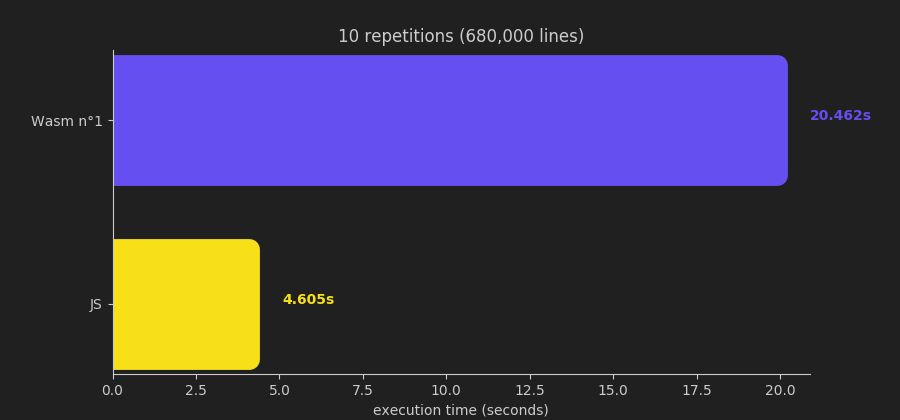
It turned out that my Wasm version was 5 times slower. I sort of knew that I should have expected that, but still, I was somewhat disappointed.
Before jumping on any conclusions it is often a good idea to check what really happens under the hood: V8 (and thus Node.js) has some good profiling tools built in, you can use them as follows:
# pass the `prof` option to Node.js
node --prof wasm.js
# This will generate a .log file, in my case isolate-0x49a1aa0-11836-v8.log
# This file can be used to generate a profile:
node --prof-process isolate-0x49a1aa0-11836-v8.log
Here is the summary for the JavaScript version:
[Summary]:
ticks total nonlib name
2236 41.2% 95.6% JavaScript
103 1.9% 4.4% C++
59 1.1% 2.5% GC
3082 56.9% Shared libraries
And the Wasm version:
[Summary]:
ticks total nonlib name
5949 20.2% 37.0% JavaScript
9405 32.0% 58.5% C++
1554 5.3% 9.7% GC
13326 45.3% Shared libraries
712 2.4% Unaccounted
The JavaScript row accounts for both JavaScript and WebAssembly code, while Shared libraries accounts mostly for Node.js built-in functions.
Something clearly goes wrong with my Wasm version: 32% of execution time is spent on C++ while it is only accounting for 1.9% in the JS version. You can also notice that the garbage collector (GC) is doing five time more work in Wasm that in JS.
Let’s take a closer look at those categories in the case of Wasm:
[JavaScript]:
ticks total nonlib name
3166 10.8% 19.7% Function: *fast_match::Matcher::run::hdc325dfd51ff7151
846 2.9% 5.3% LazyCompile: *module.exports.__wbindgen_string_new /home/gripsou/Documents/projects/fast-match/pkg/fast_match.js:135:48
687 2.3% 4.3% Function: *<alloc::vec::Vec<T> as core::ops::deref::Deref>::deref::h598faf2834c73f9f
183 0.6% 1.1% LazyCompile: *getEncodingOps buffer.js:644:24
158 0.5% 1.0% LazyCompile: *<anonymous> /home/gripsou/Documents/projects/fast-match/node/asm.js:9:49
149 0.5% 0.9% Function: *js_sys::Array::push::h20c97c9f2647281f
148 0.5% 0.9% LazyCompile: *module.exports.__wbg_push_446cc0334a2426e8 /home/gripsou/Documents/projects/fast-match/pkg/fast_match.js:176:54
107 0.4% 0.7% LazyCompile: *module.exports.__wbindgen_object_drop_ref /home/gripsou/Documents/projects/fast-match/pkg/fast_match.js:131:53
...
Most of the time spent executing my code is spent inside my Wasm run function responsible for executing the automaton, that’s a good thing. Then comes the glue code generated by wasm-bindgen, it’s JavaScript code. As indicated by the LazyCompile name, Node tried to compile our JS and succeeded (there is a *, if the code was interpreted we would have seen a ~), so our JavaScript is fast too.
Up to this point things looks good, let’s take a look at the C++:
[C++]:
ticks total nonlib name
749 2.5% 4.7% _int_malloc
673 2.3% 4.2% __GI___libc_malloc
532 1.8% 3.3% __GI___pthread_mutex_lock
513 1.7% 3.2% node::i18n::(anonymous namespace)::ConverterObject::Decode(v8::FunctionCallbackInfo<v8::Value> const&)
481 1.6% 3.0% v8::internal::PrototypeIterator::Advance()
385 1.3% 2.4% __pthread_mutex_unlock_usercnt
344 1.2% 2.1% node::Buffer::Copy(node::Environment*, char const*, unsigned long)
332 1.1% 2.1% v8::Object::SetPrototype(v8::Local<v8::Context>, v8::Local<v8::Value>)
319 1.1% 2.0% void node::Buffer::(anonymous namespace)::StringSlice<(node::encoding)3>(v8::FunctionCallbackInfo<v8::Value> const&)
285 1.0% 1.8% v8::ArrayBuffer::GetContents()
The two first items are related to memory allocation, we also spot a buffer copy operation and some encode and decode primitives. So here we are: I was copying things in memory between JavaScript and Wasm. Note this can also explain the higher load on the GC we noticed earlier.
And here is the culprit:
pub fn run(&self, string: String) -> js_sys::Array {
...
}
My interface between JavaScript and WebAssembly was using Rust strings, when reading wasm-bindgen doc, we can learn that not only strings are copied back and forth between JS and Wasm, but also that JavaScript is using UTF-16 and Rust UTF-8, meaning that there is an additional conversion overhead.
Fixing things up
In fact, I was aware of these copies between JavaScript and WebAssembly, but did it purposefully because I used to think that back and forth between JS and Wasm were slow, turns out that is not the case.
What this all means is that in this case it is much better to work with JavaScript values from Rust, the js-sys crate exposes everything that is needed for that: we can accept JavaScript string (that is a pointer to the memory hosting the string in the JS heap, no copy) and iterate over it, each character is represented by a u16:
pub fn run(&self, string: &js_sys::JsString) -> js_sys::Array {
...
for c in string.iter() {
...
}
...
}
Let’s check the performances again:
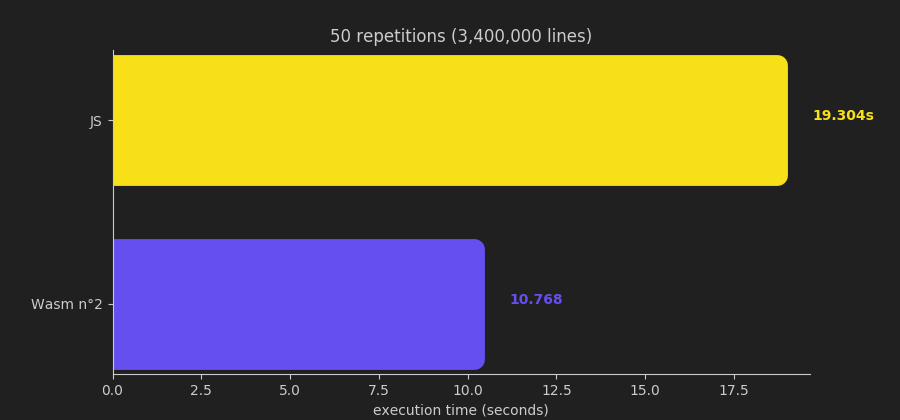
Yep, this time it is faster! It’s quite impressive considering that with today’s engines JavaScript is already really fast once JIT compiled.
Let’s take a look at the profile to check if we fixed things up:
[Summary]:
ticks total nonlib name
8249 84.7% 89.5% JavaScript
89 0.9% 1.0% C++
39 0.4% 0.4% GC
529 5.4% Shared libraries
874 9.0% Unaccounted
That is indeed much, much better: C++ code went down from 32% to 0.9% of execution time, now Node is truly spending most of its time actually executing our JS and Wasm code! Notice that the GC has also much less work to do, even less that in the pure JS version.
To put things in perspective, here is a visual recap of the old and new version profiles side to side:

Conclusion
I hope you found this post interesting, if you have to remember anything from it here are some key takeaways:
- Wasm can indeed speed up your code, but it must be handled carefully: pay extra attention to your interfaces with JavaScript, especially if you are passing data around.
- A profiler can help to find what is wrong with your code or confirm your hypothesis.
- JavaScript is already fast, maybe you don’t need Wasm to speed up your JS. For similar tasks you should not expect an order of magnitude improvement by using Wasm instead of JS.
To conclude here is a visual summary of the achieved results:
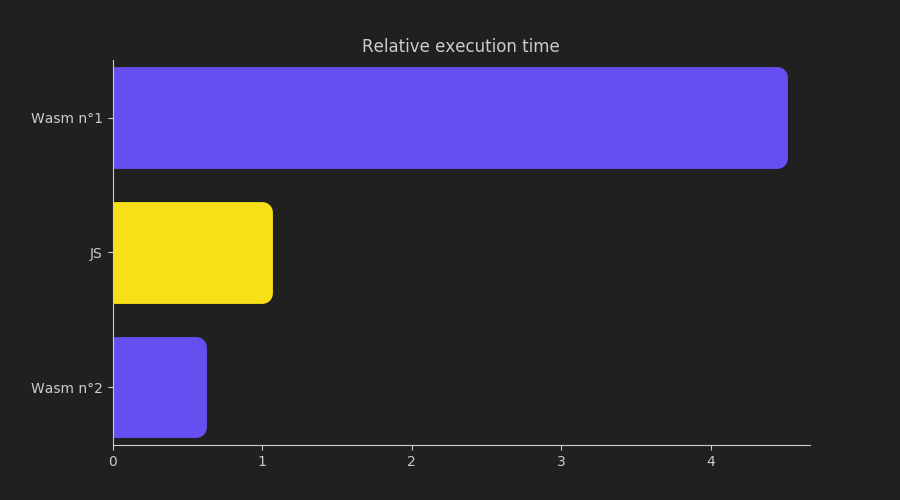
So here is the answer: Yes, once done correctly, replacing JS with Wasm can speed up my lambda function by factor of almost 2. It is now up to you to decide whether it is worth introducing Wasm into your project, considering the task you are trying to solve.