5 minutes
Introducing Parrot

I recently published my very first crate, a new step in my journey learning rust. I really enjoyed developing it and as it started becoming usable enough for my own needs I decided to publish it, so let’s do it properly!
Before jumping in and telling you what that crate actually is about, let’s start with some context.
This code does not compile
As a hobby project for the last couple of months I have been building my very own compiler. The project was going well: I built the lexer, the parser, a typing system and a custom backend and then finally ran my first program in my very own language.
I started adding end-to-end tests as soon as the full pipeline was working, that is easy to do for a compiler: collect a list of correct programs, compile them, run the binary and check that your program exits with the expected value.
But that only works for correct programs.
However, a compiler really has two jobs:
- Compile correct programs
- Help you figure out why a wrong program is wrong.
How about wrong programs now? Ideally a compiler has some sort of error reporting mechanism, and I put efforts into building one, so you expect it to produce rich and meaningful errors.
But now how do you test your error messages then? Well, you expect them to either stay the same or to improve over time. Hard-coding the errors for each test really looked like a bad idea because of the maintenance burden, instead I quickly became interested again in something I used a while ago in a different context: snapshot testing.
Can you remember that for me?
I discovered snapshot testing while doing web development with Jest, a JavaScript framework for testing React components. The way it works (or at least worked a few years back) is by literally taking snapshot of a serialized version of your components, then each time you re-run the tests Jest tells you if a component changed.
So here is the idea: I have a bunch of wrong programs, I want my compiler to generate errors for each of them and be able to check that errors do not change over time, or if they do I want to be able to check if the newer improve over the latter.
I looked for a tool doing this automatically, but I couldn’t find something that really did what I wanted… Anyway, challenge accepted.
Parrot?
Let me present parrot, a snapshot CLI tool that makes end-to-end testing a piece of cake!
Why parrot? Well, it can repeat the output of a program if you ask it to… Plus I like birds.
It’s a breeze to set up and use, let me walk you through:
You first need to initialize parrot in your directory, that’s as easy as parrot init. Then we will ask it to remember the output of a command of our choice: parrot add 'echo "Hello, world!"'. Finally, let’s check that the output didn’t change: parrot run. Done.
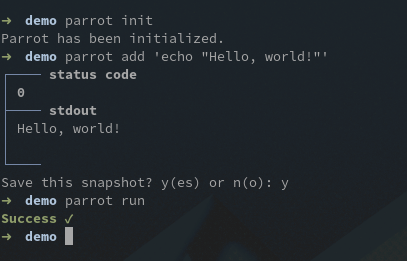
Let’s add some spice with a command whose output actually change: parrot add date.
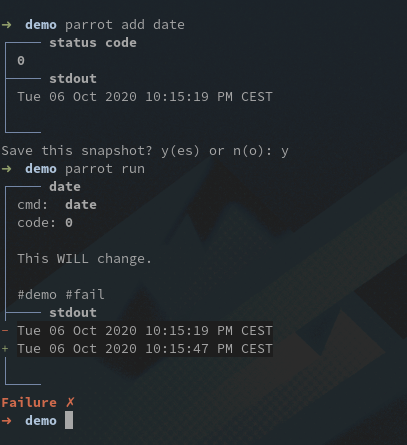
And voilà! You get a failure with a diff of the outputs, so that you can decide whether the change is a regression or not by yourself.
A few tricks
Let’s imagine that we are developing a command line tool, let’s say jq for the sake of example, how could we use parrot to test it?
First let’s create a few json to test jq with:
echo '{"items": 2, "quality": "good", "ids": [1, 2]}' > simple.json
curl 'https://api.github.com/repos/torvalds/linux/commits?per_page=5' > linux.json
Now let’s add a few tests:
parrot add "cat simple.json | jq '.items'"
parrot add "cat simple.json | jq '.ids'"
parrot add "cat simple.json | jq '.ids[0]'"
parrot add "cat linux.json | jq '.[0] | .commit.author.email'"
parrot add "cat linux.json | jq '.[] | .commit.author.email'"
parrot add "cat linux.json | jq '.[0] | {sha: .sha, name: .commit.author.name}'"
parrot add "cat linux.json | jq '[.[] | {sha: .sha, name: .commit.author.name}]'"
A first interesting feature of parrot is that it lets you browse your tests and interact with them in a custom REPL that you can open with the parrot command.
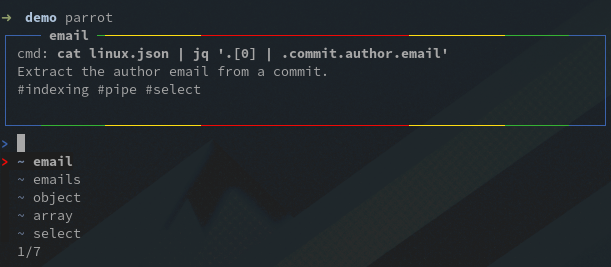
You can find the list of all available commands here, let’s just try a few of them.
Imagine you’re working on the array indexing of jq: most likely you are only interested on a few tests. Parrot lets you add a description for each test, you can add tags in that description and later filter tests on them.
For this example I created an #indexing tag, now I can filter the tests with the filter #indexing command, or f #indexing for short, then run the selected tests: run * or r * for short:
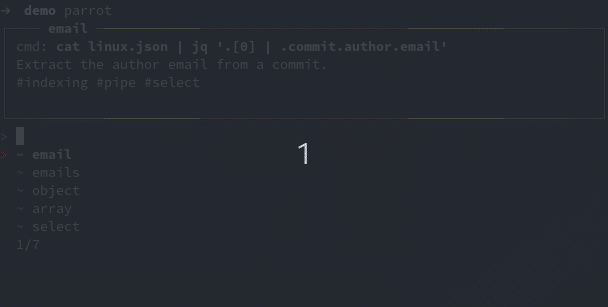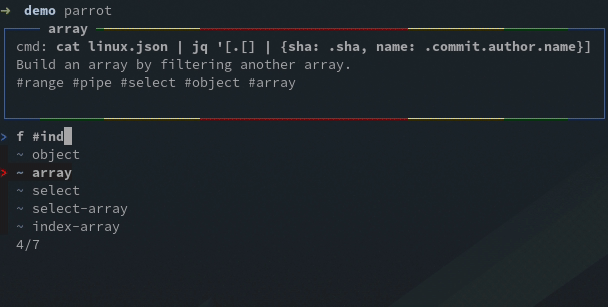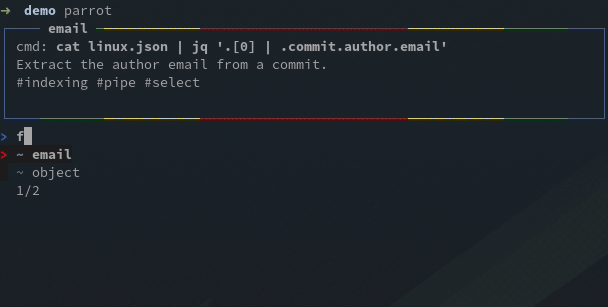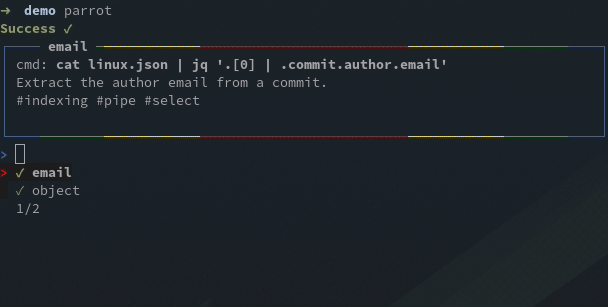
You can also execute the same parrot commands from the CLI, which can be handy for scripting purpose:
parrot exec 'filter #indexing; r *'
Conclusion
And that’s already it for this short presentation of parrot, feel free to try it and don’t hesitate to open an issue, for both feedbacks and bugs!
Personally I’m using parrot more and more in my own projects, and will continue to work on it until that it can scale to hundreds of tests.