13 minutes
Building a Memory Allocator for WebAssembly
While waiting for the GC proposal, the only way to request memory in WebAssembly is to allocate it for ourselves from the linear memory. Memory allocation and management is a huge topic in computer science, but in this post we will focus on a simple design: the linked list allocators.
Building an efficient allocator is notoriously hard, as testifies the popular jemalloc which is famously known for its 30,000 lines of codes.
In the context of programming languages, the memory allocator is both heavily influenced by the language design and influences the language itself: the Go allocator has a huge focus on concurrency with thread local memory pools, while OCaml integers are only 63 bits longs because the lowest bit is used by the GC to differentiate integers from pointers (that is why there is an int64 module).
As you will see, linked list allocators are slow, the malloc operation takes O(n) steps, but they are also very flexible and are often used as a basis upon which more sophisticated allocation methods can be built.
A list of blocks
Linked list allocators are conceptually simple: they consist in a (linked) list of blocks, when an allocation of size s is requested the allocator iterates through the list, selects a block of size at least s and removes it from the list before returning a pointer to the first byte of that block.
A block usually consist of a header and a body that correspond to the available memory. The header is used to store meta-data: the block size and sometimes a few flags, while the body contains the pointer to the next block if it’s free and some user data otherwise.

The allocator algorithm can be summarized in a few lines:
def malloc(size):
for block in block_list:
if block.size >= size:
list.remove(block)
return block
print("Out of memory")
def free(block):
list.append(block)
Such an allocator that return the first big enough block is said to use a first fit strategy, another common strategy is the best fit, where the smallest block that is big enough is returned.
There are a few subtleties, however.
The first one is that we may only have blocks that are too big, imagine having only 64 bytes blocks and being asked a block of size 8. To save memory the solution is simply to break the block in two such that one of these new blocks has a size of 8.
But this may leads to the opposite problem: what if now all our blocks are too small? We should be able to merge two contiguous blocks into a bigger one. This operation is called block coalescing.
In some case we may not be able to coalesce blocks, imagine our memory consists of two blocks of size 64 separated by a small 4 bytes block: it is no longer possible to allocate a 100 bytes block even though there is technically enough memory, we said that the memory is fragmented.
The other subtlety is alignment. In Web assembly alignment has no effect on the semantic, meaning that it does not change the program behavior, but it may affect performances.
A 32 bits load is aligned if its address is a multiple of 32 bits (or 4 bytes), and as you expect a 64 bits load is aligned if its address is a multiple of 64 bits (or 8 bytes).
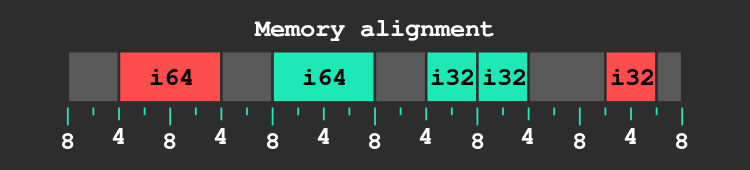
To put it simply, the hardware is not not wired to read unaligned values, and thus we should strive to avoid unaligned loads as much as possible.
The allocator design
The design space is huge, choices had to be made and for this post I propose the following:
- First fit strategy.
- Memory blocks are aligned to 8 bytes.
- Doubly linked list.
- Coalesce on free.
In WebAssembly the largest load can fetch 64 bits (or 8 bytes) and thus an alignment of 8 bytes is safe for any purpose.
Ok, but why a doubly linked list? That’s because we will need the two way linking to be able to free blocks in O(1) while coalescing at the same time.
When free is called, it will look at the two neighbouring blocks and merge any free block with the one that is being freed. This may require to remove an arbitrary block from the linked list, that is why we need to have pointers in both direction: so that we can glue the two ends together when cutting the chain.
In fact you will see that we will also need footers, otherwise there is no way to check if the preceding block is free.
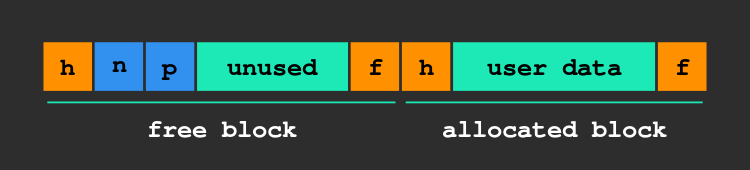
You may think that all of this makes a lot of wasted space, and it’s true, but the thing with WebAssembly is that memory addresses are only 32 bits long, thus we only need 8 bytes of “wasted” space (4 bytes of header, 4 of footer) plus a minimum of 8 bytes reserved for the body of the blocks so that we can store two pointers inside.
If you want to see different trade-offs, you can have a look at this excellent post which discusses allocator design in the context of a kernel.
Hands on code
Before diving into some code, we need to think a little bit about the initial state of the memory (the compiler might help us, or we may write a separate init_malloc function).
We will need a pointer to the first free block, which may be anywhere, escpecially if the Data section initializes some part of the memory.
We can store that pointer anywhere we like, as long as malloc can reach it.
A global variable can do the job, in this post I will store it at the very begining of the linear memory (at index 0).
Without further ado, let’s write that malloc function:
The language I’m using here is called Zephyr, it’s a small language I created for learning purpose. It should be pretty straight forward to translate it to your favorite language.
fun malloc(size i32) i32 {
let addr = read_i32(0) // Address of the first free block
let target_size = get_real_block_size(size)
while true {
if addr == 0 {
panic() // Out of memory
}
if read_i32(addr) >= target_size {
let block_size = split_block(addr, target_size)
remove_block(addr)
let header = block_size | 0x80000000 // set allocated bit
set_i32(addr, header) // header
set_i32(addr + block_size, header) // footer
return addr + 4
}
addr = read_i32(addr + 4) // go to next block
}
}
Let’s recap what happens here:
First we read the memory at index 0, remember that its where we decided to store the pointer to the first block.
Then we compute the minimal size of the block, it’s not equal to the size passed to malloc for two reasons:
- We have to store a few meta-data in that block, at least two pointers and a footer.
- We have to carefully pick a size such that the next block has the right alignment.
Let’s postpone the choice of the size for now, the next thing to do is to iterate over the list of block until we find one that is big enough.
We have to talk a little bit about the header now, it’s a 32 bit value in which we store two things:
- a flag (the 32nd bit) set to 1 if the block is allocated, 0 otherwise.
- the size of the block in the remaining 31 lowest bits.
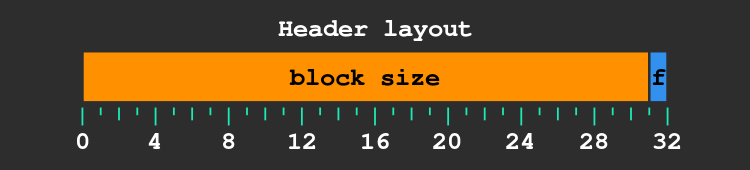
This layout allows to directly read the size of free blocks with a memory load at the address of the header: that’s exactly what we’re doing to check if the block is big enough.
From here there are two possibilities:
- The block is too small, in which case we can get the next block by following the
nextpointer (that we can read atheader_address + 4). - The block is bigger than our target size 🎉
In the latter case, we can try to split the block in two, this avoid wasting too much memory by creating a new free block with the excess space. Then we remove the block from the free list, compute the value new header (its size plus the 32nd bit set to 1) and set both the header and footer to that value and finally return the address to the free space (the first byte after the header).
As you see it’s not that complicated, there are a few details to pay attention to, but the algorithm is relatively simple. Let’s move to free now, it’s basically the reverse operation:
pub fun free(ptr i32) {
// get back the address of the header
let addr = ptr - 4
// insert the block in the chain
let old_root = read_i32(0)
if old_root != 0 {
set_i32(old_root + 8, addr)
}
set_i32(0, addr)
set_i32(addr + 4, old_root)
set_i32(addr + 8, 0)
// mark the block as free
let header = read_i32(addr) ^ 0x80000000 // unset allocated bit
set_i32(addr, header) // header
set_i32(addr + header, header) // footer
// coalesce block with neighbours, if possible
try_coalesce(addr)
}
Nothing fancy here, we compute the address of the header (4 bytes before the pointer we gave back with malloc),
then we insert the block at the beginning of the free list using the fact that the next and previous pointers are respectively 4 and 8 bytes after the header.
To remove the ‘allocated’ flag, we use a xor between the header and 0x80000000, which is a 1 followed by 31 zeroes: this will left the 31 lowest bits unchanged, but because the 32nd is set to 1 it will be reset to 0.
Finally comes the time to coalesce our blocks into bigger ones.
I don’t want to throw too much code into your face, you can check it here if you want, so let’s just talk about the main idea.
We can easily find the header of the next block because we know the size of our block, if it happens to be free (the ‘allocated’ flag is set to 0) we can merge both blocks into a single one.
Remember that we also maintain a footer? Here comes its moment of glory: its sole purpose is to allow coalescing. Because both the ‘allocated’ flag and the size is encoded in the footer, we can (if the block is free) get the address of its header (using the size in the footer) and merge both blocks.
Let’s come back to the get_real_block_size function we used in malloc, the choice of the real size of the block is crucial for preserving the alignment:
imagine if the user asks for a block of 12 bytes, we break a block to create one of size 12 and another one with the space left, here is what happens:
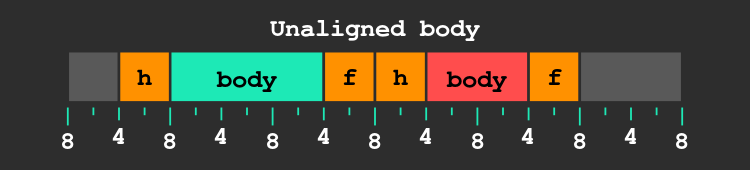
As you can see, the next block’s body is only aligned to 4, we are breaking our part of the contract, which may result in unaligned reads and a drop in performance.
Remember that our target alignment for block bodies is 8 bytes, thus because the header is 4 bytes long, our header must have an alignment of 4 (but not 8!) to ensure the desired alignment of the body.
The fix is simple, even if the user asked for 12 bytes, let’s give him 16:
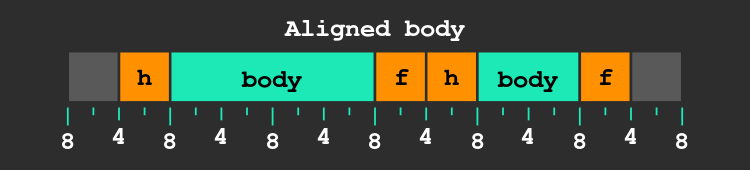
As you can see, the alignment is now back to what is expected.
Now that we are aware of that, let’s discuss the get_real_block_size function:
Beside the 4 bytes header there must be enough room for two 4 bytes pointers plus a 4 bytes footer, thus the minimal block has 12 bytes of body + footer, and we can check that with a size of 12 the next block will have the required alignment, perfect.
Now if the caller requests n bytes of body, n > 8, how much should we allocate to preserve the alignment?
Simple, we know that the body has an alignment of 8, thus body_size + footer_size + next_header_size = body_size + 8 must be a multiple of 8, in other words the body size must be a multiple of 8, and we add 4 bytes for the footer.
Here is a way do to just that in a few lines:
fun get_real_block_size(size: i32): i32 {
if size <= 8 {
return 12
}
let body_size = (size + 0b111) & -0b1000
return body_size + 4
}
Here we used a trick to compute the body size: the & -0b1000 operation cleans the 3 last bits, because WebAssembly uses two’s complement arithmetics and thus -0b1000 evaluates to 0b1111....1111000(with 32 ones and zeroes).
Thus, (size + 0b111) & -0b1000 evaluate to size itself if it’s already a multiple of 8, or to the next multiple of 8 otherwise.
And with this, we have seen most of the interesting parts of our linked list allocator, congrats for sticking with me this far 🎉
A final remark
Ok great, we have built an allocator, but it runs in O(n), it doesn’t look like it’s anything close to something usable in any serious language or application… Well, yes and no.
It’s clear that no one want to use an O(n) function for every single memory allocation, but there are ways to mitigate that: we can organize our memory better.
Usually, the memory is split in two big parts:
- The stack: a place where a new chunks of memory is pushed on function call, and freed on function return.
- The heap: everything else.
It’s very fast to allocate some space on the stack, it’s basically incrementing a pointer. However, because the memory is freed on function return it’s not possible to allocate object that outlive the function there, it’s the job of escape analysis to decide whether a chunk of memory can be allocated on the stack or not.
But, there is already a stack in WebAssembly right?
Yes, that’s true, however this stack is not addressable, we can’t have a pointer to data stored there. That’s why LLVM for instance uses a shadow stack, it’s basically another stack that lives in the linear memory and that can be directly addressed.
Unfortunately, we can’t allocate everything in the stack, and we don’t want to pay O(n) per heap allocation.
A frequent solution to this problem is to use segregated lists, where instead of having a single free list with blocks of various sizes, we can maintain a bunch of lists with fixed block sizes, let’s say 8, 16, 32, 64 and so on…
When the user requests a block, we round the size up to the next power of 2 and take the first block of the corresponding free list, that’s O(1) for the allocation, and we put it back in the list on free, that’s O(1) too.
But what happens when there is no block left in the segregated free lists or when the stack is full? We fall back to our O(n) allocator to get some more memory to grow the stack or add a few blocks to the segregated lists!
Conclusion
Thank you for reading that far! I hope you enjoyed this article and learned a thing or two about memory mangement or WebAssembly. If you have any question, remark or feedback don’t hesitate to open an issue here.
If you want, you can also play with the allocator online right here.